Query processing
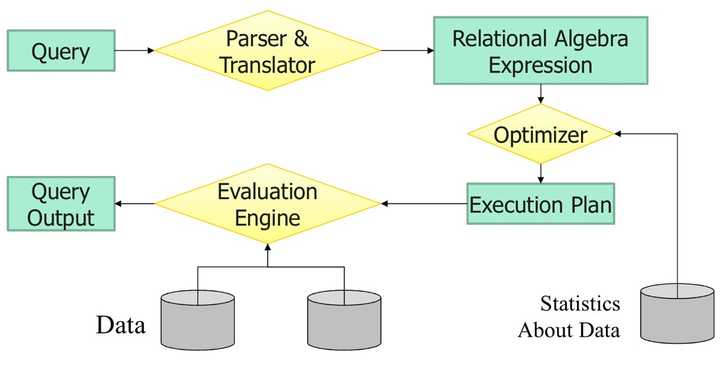
DBMS의 질의 처리는 일반적으로 다음과 같은 세 단계로 구성됩니다.
-
Parsing & Translation
Parsing: 사용자로부터 입력된 쿼리문을 해석하고 문법적으로 올바른지 확인하는 단계
Translation: 구문 분석된 쿼리를 내부적으로 사용하는 형식으로 변환
SQL 쿼리를 내부적인 데이터베이스 시스템이나 엔진이 이해할 수 있는 형태로 변환
관계대수식 또는 기타 형태의 중간 표현으로 나타낼 수 있습니다.
-
Optimizer
쿼리 실행 비용을 분석하여, 변환된 쿼리 또는 관계대수식을 실행하는 데 효율적인 방법을 찾는 단계
쿼리의 실행 계획을 결정하고 가장 적절하게 수행할 수 있게 인덱스 사용, 조인 순서 변경 등과 같은 다양한 방법중 비용이 적은 방법을 추론(estimate)합니다.
-
Evaluation
최적화된 실행 계획을 기반으로 실제로 쿼리를 실행하고 결과를 생성하는 단계입니다. 데이터베이스 시스템은 최적화된 계획에 따라 데이터를 액세스하고 처리하여 사용자가 요청한 정보를 생성합니다.
질의 실행 비용을 결정 요인들
- 디스크 액세스 시간
- 질의를 실행하기 위한 CPU 시간
- 통신 시간 (분산/병렬 질의)
가정
- 디스크 액세스 시간이 가장 중요한 요인
- 각 디스크 블럭을 액세스하는 시간은 동일
- 질의의 최종 결과를 디스크에 기록하는 시간은 고려하지 않는다.
Query Optimization
정의
주어진 질의에 대한 최선의 실행 방법을 발견
데이터 모델에 따른 Query Optimization
Catalog Information
Relation의 통계 정보를 저장
| 속성 | 설명 |
|---|---|
nᵣ |
# of records in r |
bᵣ |
# of blocks containing records of r |
sᵣ |
Size of a record of r in bytes |
fᵣ |
Blocking factor of r (bᵣ = 〈nᵣ/fᵣ〉) |
V(A, r) |
# of distinct values that appear in r for 속성 A |
If A is a key for r, V(A, r) = nᵣ |
|
SC(A, r) |
Selection cardinality of 속성 A of r |
| SC(A, r) = nᵣ / V(A, r) |
Information about Index
| 속성 | 설명 |
|---|---|
fᵢ |
The average fan-out of internal nodes of index i |
HTᵢ |
The height of index i |
B+ Tree |
HTi = 〈logfi(V(A, r))〉 for B+ Tree indices |
HashIndex |
HTi = 1 for Hash Indices |
LBᵢ |
# of blocks at the leaf level of index i |